From Dense Monoliths to Modular Minds: The Rise of Symbolic Routing in LLMs
The history of Artificial Intelligence (AI) has largely been defined by a dichotomy: the flexible, probabilistic learning of Connectionism versus the rigorous, compositional logic of Symbolism. However, the emergence of Large Language Models (LLMs) is fostering a synthesis of these paradigms through a fundamental architectural shift: the move from Dense Monoliths to Modular, Routed Systems. This shift is fractal. At the Macro level, LLMs function as central planners, using symbolic protocols to orchestrate external tools and specialized neural agents. Simultaneously, at the Micro level, the models themselves are evolving into sparse, modular structures (such as Mixture-of-Experts) governed by internal routing mechanisms. In this post, we explore this transition toward Symbolic Routing. We discuss how this paradigm enables us to build societies of neural agents, discover latent modularity within dense networks, thus enabling composable, verifiable, interpretable and continually learnable AI system. And we also discuss how to leverage these structures to synthesize training data and formally verify AI reasoning.
Introduction: The Neuro-Symbolic Renaissance
Artificial Intelligence (AI) has long swung between two poles. On one side is Symbolism, the tradition of explicit rules, logic, and step-by-step reasoning. On the other is Connectionism, the belief that intelligence emerges from pattern recognition in large neural networks. This divide mirrors an old philosophical tension between rationalism and empiricism
Symbolic AI, which dominated from the 1950s to the 1990s, is rooted in the explicit manipulation of human-readable symbols according to logical rules
Connectionist AI, inspired by the biological brain, posits that intelligence emerges from vast networks of simple units (neurons) learning from data
Today, we are seeing a third phase emerge: the rise of the router. Modern LLMs possess an emergent mastery of both distributional representations and discrete tokens (e.g., code, SQL, JSON)
- Macro-Symbolism (System Level): The LLM becomes a Planner, deciding when and how to call a database, a coder interpreter, a JSON API request, or which specialized model to invoke. In effect, it routes tasks across a society of tools and agents.
- Micro-Symbolism (Model Level): Inside the LLM itself, we see a shift from dense monoliths to modular, sparse structures. Mixture-of-Experts (MoE) architectures introduce explicit routers that choose which internal “experts” to activate, while mechanistic interpretability reveals latent circuits that already behave like implicit modules.
In this post, we explore how this shift—from dense models to routed, modular minds—is reshaping both AI systems and the models that power them. We start with Macro-Symbolism: the probabilistic-deterministic loop that lets LLMs ground their answers in external tools and orchestrate specialized neural agents. Then we zoom in to Micro-Symbolism: how routing and modularity are emerging inside the model itself, from explicit MoE experts to latent circuits discovered via interpretability. We discuss how these two kinds of symbolism benefit future LLM system. Finally, we discuss how these routed architectures enable two critical capabilities for the next generation of AI systems: automatic data synthesis and verified reasoning.
Macro-Symbolism: The Planner-Executor Paradigm
The first major shift toward a modular AI architecture is happening at the system level. We call this Macro-Symbolism. In this paradigm, the LLM stops acting as a solitary “Oracle” and instead becomes a Router: a central planner that orchestrates external modules to solve problems.
This architecture is built on a simple division of labor. The connectionist “Brain” (the LLM) handles ambiguity, planning, and language. The specialized “Hands” (external modules) handle concrete execution. They talk to each other through structured protocols: explicit symbolic languages such as SQL, JSON, or Python code. In practice, this routing happens in two main ways:
- Routing to deterministic tools: “Glass box” systems like calculators, databases, search engines, and code interpreters, whose behavior is transparent and verifiable.
- Routing to neural specialists: “Black box” systems such as vision models or other LLMs, which act as experts for perception, generation, or domain-specific reasoning.
The Core Mechanism: The Probabilistic–Deterministic Loop
Despite their linguistic prowess, standalone LLMs remain limited: their knowledge is frozen at training time, they are prone to confident hallucinations, and they are effectively “brains in a jar”, disconnected from the external world. The hybrid neural–symbolic paradigm addresses these issues by pairing the flexibility of LLMs with the rigor of deterministic programs
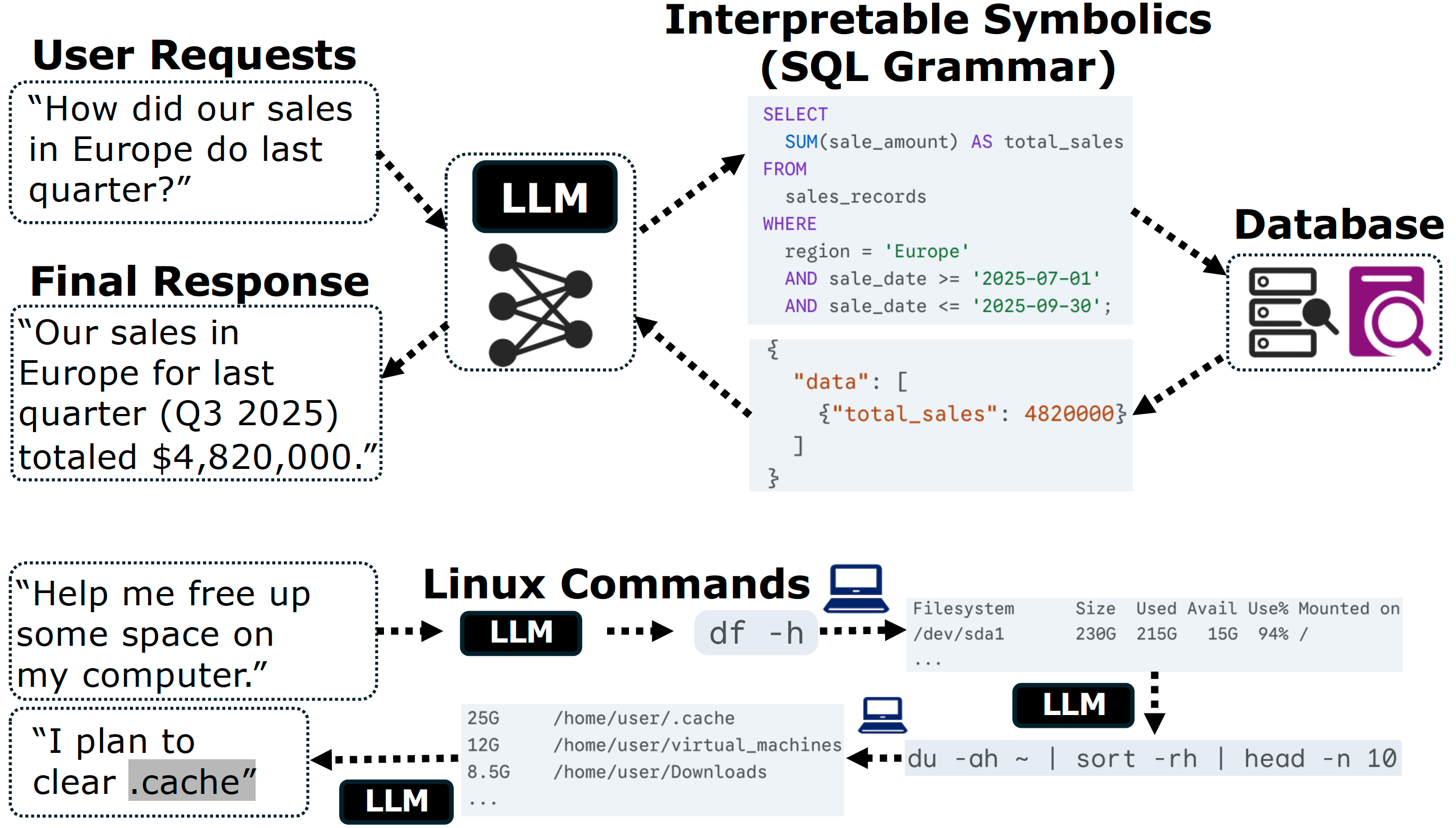
In this architecture as shown in Figure 2, the LLM serves as an intuitive semantic interface, while the external program (a search engine, database, Python interpreter, or theorem prover) plays the role of verifiable executor. The key step is translation: the LLM converts user intent into a precise, logically interpretable symbolic intermediate representation (IR).
The Four-Stage Cycle: Input, Translation, Execution, Grounding. Most tool-augmented systems follow the same four-stage loop:
- User input (fuzzy intent). A person describes a goal in natural language, such as “How did our European sales do last quarter?” or “Help me clean up my hard drive.”
- Translation (symbolic bridge). The LLM acts as a natural-to-formal compiler, turning this fuzzy request into an unambiguous IR: a SQL query, a Python script, or a JSON API call.
- Execution (glass box). IR is passed to a deterministic program that executes it faithfully. Unlike the neural network, this component is a “glass box” with transparent and predictable behavior.
- Grounding (factual synthesis). The results (e.g., table, calculation, search snippet, or proof state) are fed back into the LLM, which synthesizes a fluent answer grounded in these verifiable outputs
.
Verifiability and control. This loop introduces a natural firewall between the probabilistic model and the real world. The LLM never executes actions directly; it proposes a plan in the form of symbolic code. That code can be logged, inspected by humans, analyzed by static tools, or rejected before it is run. This kind of auditing and intervention is difficult to achieve in end-to-end neural systems.
Computational integrity. Connectionist models excel at pattern recognition but struggle with tasks that demand exact arithmetic or strict logical rules. Rather than memorizing multiplication tables, a tool-augmented LLM can write Python or formulate an optimization problem, then delegate the actual computation to a solver. This separates reasoning about the problem (neural) from computing the solution (symbolic), combining linguistic fluency with mathematical rigor.
Dynamic extensibility. Finally, symbolic routing breaks the “parametric knowledge boundary”. Instead of retraining the model every time the world changes, we can hook it up to new tools by defining new schemas and APIs. Adding a live stock feed, a proprietary enterprise database, or a theorem prover becomes a matter of describing the interface, not touching the weights. The LLM evolves from a static text generator into an agentic controller of external systems.
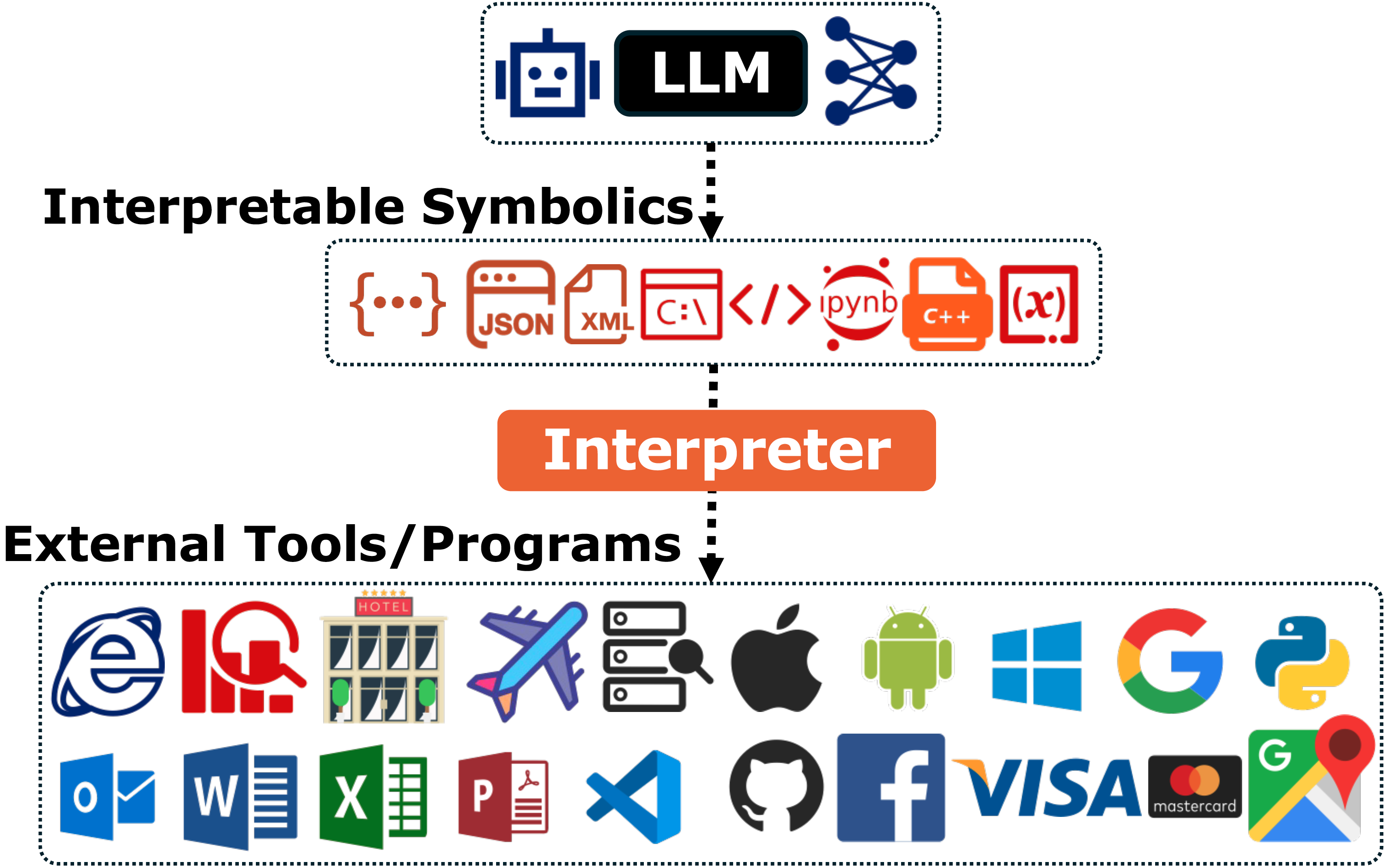
Applications: From Fuzzy Language to Interpretable Actions. Although the tools differ, the same probabilistic–deterministic loop appears across many domains:
- Information access. The model converts questions into search queries or Text-to-SQL statements, then grounds its answers in retrieved web pages or database rows
. - Code and data analysis. Instead of doing arithmetic in its head, the LLM writes and runs Python in a sandbox, using the results to answer questions about files, logs, or datasets
. - System and service control. Natural language instructions are translated into shell commands, GUI scripts, or JSON API calls that interact with servers, legacy software, or cloud services
. - Formal reasoning and robotics. High-level intents become Lean tactics for a theorem prover
or control commands for a robot, with the symbolic engine (kernel or controller) enforcing correctness and safety .
Across all of these, the pattern is the same: the LLM transform fuzzy human language into executable symbolic languages for an automatic program to interpret or execute.
Scaling to Neural Modules: The Agentic Workflow
So far we have focused on tools like databases, search engines, and interpreters. The next step is to treat other neural networks as tools as well. Instead of building a single, monolithic model that tries to do everything, we can compose smaller experts behind symbolic interfaces. This mirrors the evolution of software from monoliths to microservices
Wrapping Neural Networks in Symbolic Interfaces. Any system that accepts structured input and produces predictable output can be wrapped in an API definition. This lets a central planner treat highly specialized models as if they were ordinary Python functions
- Perception. Vision and audio models (CNNs, ViTs, speech recognizers) perform OCR, object detection, or transcription more efficiently than a general-purpose multimodal LLM
. - Generative media. Diffusion models act as the system’s “imagination”, turning text prompts into high-fidelity images or videos
. - Domain experts. Models such as small, fine-tuned LLMs specialize in particular scientific or professional domains, from protein folding to legal analysis
.
From the planner’s perspective, these are all just callable tools: each has a name, an input schema, and an output schema.
The Orchestration Workflow. Consider a user who uploads a quarterly earnings PDF and asks: “Analyze this report, identify the main revenue drivers, plot them, and draft a press release.” A planner LLM can handle this without doing every step itself:
- Decompose the task. The planner breaks the request into subtasks: extract text from the PDF, analyze the financial data, generate a plot, and write the press release
. - Call the right experts. It routes the document to an OCR or document-understanding model, passes the extracted tables to a financial-analysis agent or code interpreter, and uses a plotting tool to generate visuals
. - Synthesize the answer. Finally, it folds the analysis and the chart back into a coherent narrative, written in the user’s preferred tone.
Throughout this process, the planner does not need to know how OCR, financial modeling, or plotting work internally. It only needs to understand how to speak the right symbolic language to each expert and how to route information between them.
Why Modular AI Wins. Shifting from a monolithic “God Model” to a modular system of agents offers profound engineering advantages, validating the macro-symbolic approach
- Performance via specialization. Dedicated perception or domain models typically outperform generalist LLMs on their home tasks. Divide-and-conquer yields higher quality.
- Efficiency and cost. There is no need to invoke a trillion-parameter model to perform simple OCR or schema extraction. Routing lightweight tasks to small experts reduces latency and compute.
- Maintainability. Components can be upgraded or replaced independently. Swapping in a better OCR model or a new diffusion model does not require retraining the planner.
This compositional view suggests that future AI systems may look less like a single all-knowing agent and more like a robust society of models, coordinated through structured protocols.
The Future: The Rise of the LLM-OS
As these planner–executor patterns mature, a natural analogy emerges: the LLM-as-operating-system (LLM-OS)
- Memory, via context windows, external vector stores, and retrieval mechanisms.
- Processes, by scheduling and coordinating multi-step agentic workflows.
- I/O, through drivers that expose tools, APIs, and other models as callable resources.
Two developments seem especially important. First, we are moving toward standardized agent interfaces that let diverse tools and models discover and call one another with minimal glue code
At the system level, then, modularity and routing are already reshaping how we build AI applications. Yet the core model—the neural kernel itself—remains largely opaque. In the next section, we turn this lens inward and ask: can we apply the same modular logic inside the model, not just around it?
Micro-Symbolism: The Internal Routing Paradigm
Macro-Symbolism shows how LLMs route between tools and agents outside the model. A parallel transformation is beginning to happen inside the network itself. Traditional deep learning has relied on dense, monolithic architectures where every parameter is active for every token. These models work astonishingly well, but their internal logic is heavily entangled: it is hard to tell whether a model is genuinely reasoning or simply exploiting “shortcuts”: superficial correlations in the training data that bypass causal understanding
We refer to the emerging alternative as Micro-Symbolism. The architectural logic of the planner–executor pattern is internalized: the dense block of weights is factored into distinct functional components, and information flows through them via routing mechanisms. The goal is to move from opaque pattern matching toward systems that solve problems by composing disentangled skills.
The Explicit Router: Mixture-of-Experts (MoE)
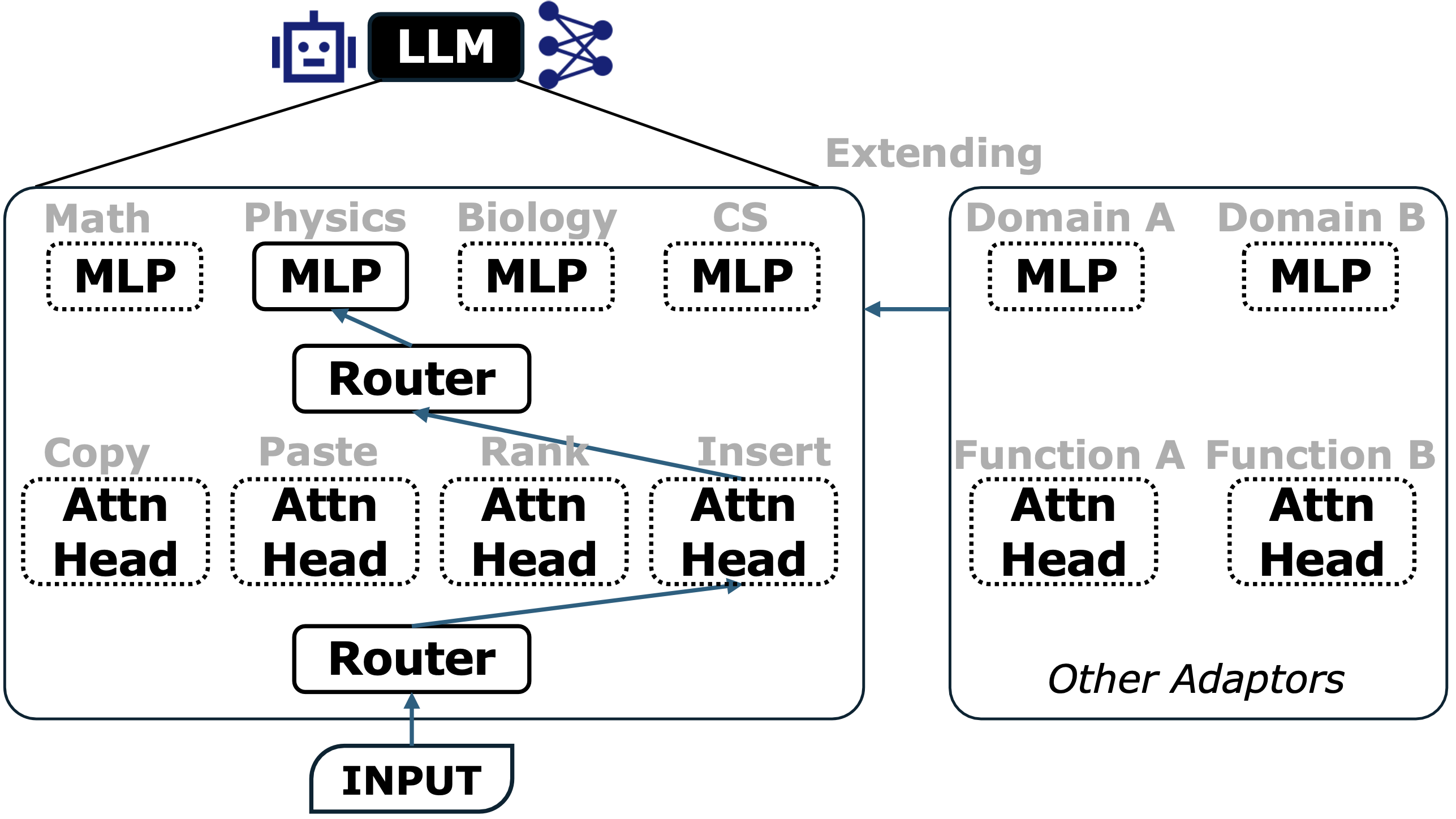
The most concrete realization of micro-symbolism is the Mixture-of-Experts (MoE) architecture. Instead of activating the entire network for every token, MoE introduce sparsity: only a small subset of parameters is used for each input
In an MoE Transformer, the standard feed-forward layer is replaced by a collection of parallel “expert” networks as shown in Figure 3. A trainable gating network (or router) sits in front of them, inspects the current token, and makes a discrete decision such as: send this token to Expert 3 and Expert 7. This is a microscopic analogue of the system-level planner. Just as an LLM routes a math question to a calculator, the MoE router can route numerically heavy tokens to a math-specialized MLP. Note that considering Attention heads are responsible for different functions, they also can be routed and sparsely activated during inference as shown in Figure 3.
These routing decisions create a quasi-symbolic bottleneck inside the network: each token is explicitly assigned to a small set of experts. Different experts can specialize in different sub-functions (e.g., syntax, factual or procedural knowledge), while the router learns to compose them on the fly. Rather than learning every new task from scratch, the model can solve novel problems by recombining pre-learned functions, much like assembling Lego blocks
The Implicit Router: Discovering Latent Modularity
Most current LLMs, however, are still dense transformers with no explicit MoE layers. At first glance, they look like undifferentiated blocks where every unit talks to every other. Yet mechanistic interpretability work suggests that even these dense models spontaneously develop a latent modular structure
The Cost of Entanglement: Shortcut Learning. Without clear internal boundaries, dense models often learn “shortcuts”: heuristics that work on the training distribution but fail under shift. Consider multimodal models analyzing charts. When shown a scatter plot of population data, a model might confidently call it a “line graph” simply because the caption mentions “population” and the points trend upward.
We can view this as a routing failure. The model likely contains a perceptual circuit capable of distinguishing dots from lines, but the internal controller does not reliably route the signal through it. Instead, the model takes an easier path: a linguistic shortcut (“population” $\Rightarrow$ line graph) or a prior-knowledge shortcut (populations usually grow). Because the “seeing” circuit and the “guessing” circuit are entangled, the stronger heuristic overrides perception.
Uncovering the Latent Router. These failures do not mean that dense models are structureless. They indicate that the structure is latent and poorly controlled. Careful probing shows that transformers already organize themselves in modular ways:
- Layer-wise specialization. Early layers often behave like syntactic parsers, tracking word order and surface form, while deeper layers encode more abstract semantics and factual knowledge
. - Procedural traces. In multi-step reasoning tasks, specific attention heads in LLMs track particular stages of inference, effectively acting as registers for intermediate variables
.
Viewed this way, the attention mechanism itself functions as a soft, continuous implicit router. By choosing where to attend in the residual stream, attention heads route information between different subspaces—syntactic, semantic, factual, or task-specific.
From Entanglement to Circuit Discovery. Micro-symbolism in dense models is therefore an analytical project. By applying tools from mechanistic interpretability, we can “symbolize” parts of the network: map directions in activation space to human-interpretable concepts (a gender direction, a previous-token head, a negation circuit)
Identifying these latent modules is the first step toward a more ambitious goal: post-hoc modularization, where we turn discovered circuits into explicit, controllable building blocks.
The Future: Post-Hoc Modularization and Structured Control
If dense models already approximate modularity internally, a natural next step is to make that structure explicit. Post-hoc modularization imagines taking a pretrained model and refactoring it into a transparent, composable cognitive system.
Refactoring the Monolith. Standard training optimizes for end-to-end loss, often at the expense of clean internal structure. Post-hoc modularization reverses this: using interpretability tools, we identify circuits for specific capabilities: arithmetic
This process turns the “art of alchemy” into something closer to software engineering. Once a capability is disentangled, it becomes:
- Inspectable: we can test and verify the module in isolation.
- Repairable: if a circuit encodes a bias or persistent error, we can patch it without retraining the whole model
. - Composable: robust modules can be reused across tasks or even modalities—for example, reusing a math circuit for text and vision. This aligns with ideas in model merging and adapters
, but with a more interpretable notion of what is being combined.
Structured Reasoning Controllers. To make these modules work together, we need internal controllers that play a role analogous to the planner at the system level. A structured reasoning controller would guide the flow of information between modules, enforcing process over output
Instead of letting information diffuse across all layers, the controller would explicitly route data from a perception module (to bind entities) to a logic module (to infer relationships), and only then to a language module (to verbalize the conclusion)
If Macro-Symbolism systems are for orchestrate tools and agents, Micro-Symbolism aims for models whose internal operations follow similarly modular, interpretable patterns. They point toward AI systems that do not just imitate correct answers, but earn them through structured reasoning.
Automatic Data Synthesis and Formal Verification
The move from purely connectionist black boxes to neuro-symbolic systems is not just an architectural shift; it changes how models learn and how we trust them. Whether we look at Macro-Symbolism (agents and tools) or Micro-Symbolism (MoE and circuits), two basic questions remain: where does the data come from, and how do we know the answer is actually correct?
The structured protocols that we have discussed above could do more than improve performance. They provide a foundation for two complementary capabilities: automatic data synthesis, where models generate data via formal structure and automatic programs, and formal verification, where we check their reasoning using logical proofs.
Program-Aided Data Synthesis
High-quality human text is finite, and much of it has already been scraped. Synthetic data is the natural next step, but naive approaches—“ask an LLM to write more text like the internet”—risk model collapse, where models amplify their own artifacts and drift away from reality
The planner–executor architecture in previous section suggests a different strategy. Instead of treating the model as a storyteller, we treat it as a generator of programs and simulations. Rather than hallucinating a fact, the LLM writes code or constructs an API call that derives that fact from an external system
The Mechanism: From Text to Trajectories. This perspective turns training data from static text into causal trajectories: records of successful interactions with the world. The pattern recurs across domains:
- Digital APIs and tools. To create fine-tuning data for a new API, the model can generate a user query, write the corresponding code or JSON call, execute it, and record the result. Each example is a clean
(Prompt, Code, Answer)triplet where the answer is guaranteed by the tool, not by the model’s guess. - Simulated physical worlds. Acting as a “director” for physics engines such as Unity or Blender, an LLM can script scenes, vary lighting, pose, and texture, and automatically collect perfectly labeled image–annotation pairs. This allows us to target rare or dangerous scenarios that are hard to observe in the real world
. - Agent trajectories. In interactive environments, the model can act, observe the outcomes, and record (State, Action, Reward) traces. Successful runs can then be distilled into training data for downstream RL agents, giving them a strong warm start without long periods of random exploration
.
In all three cases, we are no longer training on what people happened to write. We are training on what worked: trajectories where a plan, encoded as symbolic code, succeeded when executed.
The Curriculum: Agentic Continual Pre-training. Once we can generate large numbers of automatic trajectories, a natural next step is to use them to continually refine the base model itself. Agentic Continual Pre-training (Agentic CPT)
- Multi-turn tool use. Learning that the output of Tool A (e.g., search) should be fed into Tool B (e.g., code or analysis), and that actions have consequences over multiple steps.
- Reflection and correction. When a tool call fails, the training data includes the model’s debugging and self-correction process, teaching it how to recover from mistakes
. - Goal clarification. In ambiguous situations, successful trajectories may include the model asking clarifying questions rather than acting prematurely.
This shifts the training signal from what people say to what successful agents do. Automatic data synthesis turns symbolic routing into a data engine.
Verified Inference: The Logic of Truth
Even with better data, there is a second problem at inference time: the model’s internal logic remains probabilistic. A large LLM predicts the next token, not the next true statement
Theoretical Foundations: From Natural Language to Formal Logic. The final step in the neuro-symbolic story is to apply the same translation machinery used for tools to the model’s reasoning itself.
The core idea is simple: let the LLM reason in natural language, but verify its reasoning in a formal system as shown in Figure 4. Concretely, we translate the model’s explanations into a symbolic language such as first-order logic or the tactic language of a proof assistant like Lean
This idea has deep roots. Richard Montague’s work in the 1970s argued that natural language could, in principle, be given a model-theoretic semantics as rigorous as that of programming languages
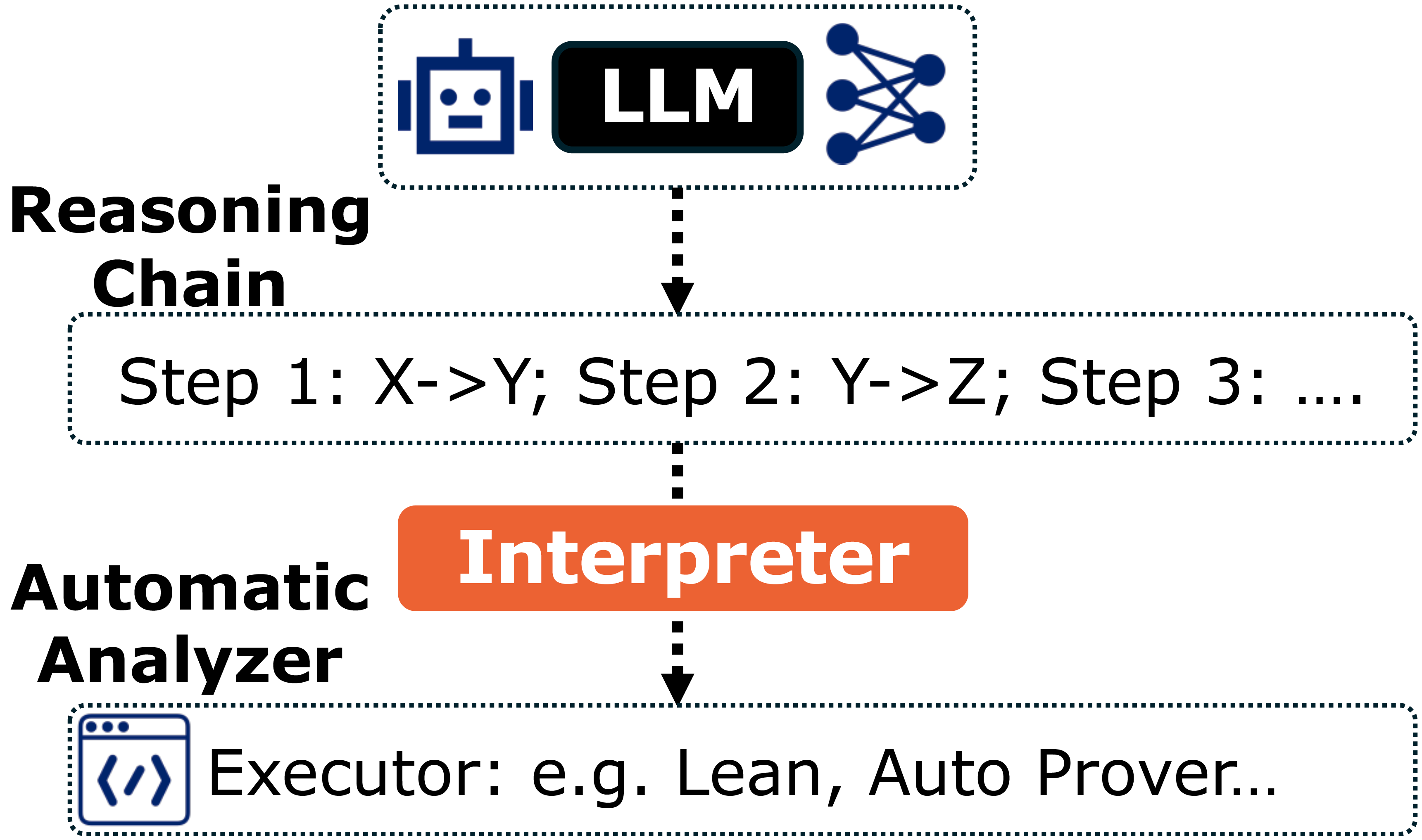
The Verification Workflow. Putting this into practice suggests a verification loop:
- Generation (conjecture). The LLM solves a problem and outputs its reasoning in natural language. At this point, the explanation is treated as a proposal, not a certified proof.
- Formalization (translation). A specialized “formalizer” model parses the explanation and translates each step into a formal claim, such as a Lean proposition or a first-order logic formula
. - Verification (proof). These claims are handed to a theorem prover or model checker, which attempts to show that each step follows from the previous ones. The prover’s kernel acts as a mathematical gatekeeper
. - Feedback (correction). If a step fails, the verifier returns a concrete error (for instance, a missing assumption or a contradiction). This feedback is fed back to the LLM, which can revise its reasoning and try again
.
The same pattern extends beyond pure mathematics. In fact-checking, natural language claims can be translated into queries over structured knowledge bases, with symbolic systems checking consistency against trusted sources
Automatic data synthesis and verified inference close the loop on neuro-symbolic AI. The former turns tools and simulations into a source of reliable training data; the latter turns logic and proofs into a way to certify reasoning at test time. Together with macro- and micro-symbolism, they sketch a path toward AI systems that are not only powerful, but also grounded and trustworthy.
Conclusion
The integration of LLMs with structured protocols marks a turning point in how we design intelligent systems. Instead of treating models as dense, all-purpose monoliths, we are moving toward modular, routed architectures—systems that plan, delegate, and compose.
At the Macro level, this means LLMs acting as planners: translating human intent into symbolic representations, coordinating tools, and orchestrating specialized neural agents. At the Micro level, the same logic appears within the models themselves, from explicit MoE routers to the latent circuits uncovered through interpretability.
Together, these trends open the door to two capabilities that dense models struggled to provide: automatic data synthesis, where data is generated through code and simulation rather than speculation, and verified inference, where reasoning can be checked against formal logic.
The path forward is not about choosing between neurons and symbols. It is about building the interfaces that let them work together—systems that can plan, reason, verify, and learn in structured, interpretable ways. As routing becomes a central organizing principle, AI moves closer to something genuinely trustworthy: intelligence that can explain how it works, not just what it outputs.
Enjoy Reading This Article?
Here are some more articles you might like to read next: